12.4 Election Day preparation
With some pre-election planning, R can help you generate on-deadline charts, graphs, and analysis. This goes the same for other expected data you’d like to analyze on a tight time frame, such as new census population data or the latest job-growth report. Planning is critical.
Sweden’s Aftonbladet newspaper went all-in with R for its election coverage back in 2014. In a blog post about their experience, Jens Finnäs said a key to successful on-deadline coverage was preparation. They decided to focus on breakdowns by municipality, and collected some data in advance. They also decided what questions they wanted to answer before results started coming in.
Additional ways you can prepare in advance:
In what format will election results be available? Knowing this will give you a head start in creating charts and graphs. Will data be in the right shape for you to analyze in your preferred R tools? If not, do you have code ready to get it prepped for analysis? If you’re pulling in national/state-wide election results from a paid service API or compiling results yourself from staff reports in the field, you may know the format in advance. If results come from a local official, maybe the format is similar each year; or you can ask in advance for a sample spreadsheet.
What would you like to do with this data? Create a searchable, sortable chart? Graphs? Maps? For election data, do you want to examine how demographics affect candidate preferences? Show which communities changed party preferences over time? Look at turnout versus demographics or results? Using results from a prior year or test data, you can set up code ahead of time to do many of these things and then swap in updated results.
This chapter’s project shows how I might have prepared to cover the 2018 Massachusetts gubernatorial race. I’ll use 2014 data to visualize results and create an interactive table. I’ll then have steps that will be fairly easy to adapt for upcoming contests.
12.4.1 Step 1: Configure data files
When cooking a meal, things work out better if you have all the necessary tools and ingredients at the start, ready on the counter as you go through your steps. It’s the same with an R “recipe” – I like to set up my data variables at the outset, making sure I’ve got “ingredients” at hand.
For my recipes, I start by creating variables with data files at the top, making it easier to re-use with other, similar data (as well as move my work from one computer to another). Also at the top, I load all packages I want in memory.
Where’s your data? I suggest giving some thought to how you want to store your data files. I spent a few years creating one R project for each election I analyzed, ending up with data and geospatial files scattered all over my computer’s hard drive. That made it unnecessarily aggravating to find geospatial files that I wanted to reuse, or pull together past election results over several years.
Later, I made one folder in my Documents directory for geofiles and another for election data, each with subdirectories for national, state, and local files. Files I’d like to use on both my desktop and laptop are in a Dropbox folder that syncs on both systems.
This may not work for you. You might want to create one R project for mapping files and another for election data. When you get more advanced (beyond what I’ll cover in this book), one of the best things you can do is create your own R package. However you decide to organize your data, it’s helpful to keep to a scheme so you know where your data and scripts are if you want to use them again.
Get the data. Data from past Massachusetts gubernatorial elections are available from the Secretary of State’s office with results by county, municipality, and precinct. I downloaded the data and included them as Excel files in this book’s GitHub repo.
I added this to the top of my script file:
##### CONFIGURATION #####
#### Voting results file locations ####
ma_gov_latest_available_file_name <- "data/PD43+__2014_Governor_General_Election.csv"
ma_gov_previous_available_file_name <- "data/PD43+__2010_Governor_General_Election.csv"Next, I’d like a geospatial file of Massachusetts cities and towns. You can import that data into R with the tigris package. Somewhat non-intuitively, getting boudaries for Massachusetts’ 351 cities and towns requires tigris’s county_subdivisions() function:
I’m pretty sure I’ll want to use these again someday. I can save the information and R structure using base R’s save() function. save(ma_cities, file = "path/to/geofiles/MA/mamap2015.Rda") saves the ma_cities object to a file in a project subdirectory called mamap2015.Rda. Multiple objects can be stored in a single file using the syntax save(variable1, variable2, variable3, file = "path/to/myfile.Rda"). You can also use the longer .Rdata file extension instead of .Rda if you’d like.
When you want to use an .Rda (or .Rdata) data object again that you created with the save() function, run load("path/to/geofiles/MA/mamap2015.Rda") (or wherever you saved it). Any R objects stored in mamap2015.Rda will be loaded into your working session, using the variable names you used to store them.
I’ll add this to my script:
There are a couple of other things you might want to set up as variables in this configuration section if you’re serious about re-use. Adding information such as chart and map headlines and source information makes it easier to re-use the script in a future year with new data from the same sources.
12.4.2 Step 2: Load packages
I usually want dplyr and ggplot2 when working with data, so I tend to load them in most R scripts I write. If you’ve got favorite R packages, you might want to do the same. For this project, I’d like the option of using magrittr for its elegant piping syntax, which I’ll cover in Step 4. And I expect to use tmap, tmaptools, and leaflet for mapping. I’ll add more packages to this section as I go on, but I’ll begin by adding this to my recipe script:
#### Load packages ####
library(dplyr)
library(ggplot2)
library(magrittr)
library(tmap)
library(tmaptools)
library(leaflet)
library(stringr)
library(janitor)
library(readr)
library(DT)Reminder: Using four or more pound signs after each section header lets me use navigation at the bottom of the script panel, as I explained in Chapter 6.
12.4.3 Step 3: Import data.
I imported both 2010 and 2014 voting results into R using the variables that hold the file name and location: ma_gov_latest_available_file_name and ma_gov_previous_available_file_name.
##### IMPORT DATA #####
#### Import election results ####
ma_latest_election <- rio::import(ma_gov_latest_available_file_name)
ma_previous_election <- rio::import(ma_gov_previous_available_file_name)When I’ve got the latest 2018 results, I can swap that file into my ma_gov_latest_available_file_name variable at the top of the script, and I won’t have to worry about remembering to change it anywhere else.
I’ll also import the shapefile here with with
12.4.3.1 Syntax shortcut
The pattern of taking a data frame, performing some operation on it, and storing the results back in the original data frame is such a common one that there’s a piping shortcut for it. mydf %<>% myfunction(argument1, argument2) is the same as
The %>% operator is availabe for use whenever you load the dplyr package. The %<>% operator isn’t. To use %<>%, you need to explicitly load the magrittr package with library(magrittr).
This syntax may make for less readable code, especially when you’re first starting out. However, it also makes for less typing – and that means less possibility for errors, especially if you have multiple objects with similar names. Decide which syntax works best for you for the project at hand.
12.4.4 Step 4: Examine (and wrangle) the data
I’ll start checking the imported data with str(ma_latest_election), head(ma_latest_election), tail(ma_latest_election), and summary(ma_latest_election) (or glimpse(ma_latest_election) or skimr::skim(ma_latest_election) ). I’ll just work with the 2014 data in this section to save space; the 2010 data would be similar.
When I ran str(), head(), and tail(), I saw a few issues. There are 352 rows instead of 351, and – from tail() as you can see in Figure 12.1 – the last row is a total row that I don’t want for the map (that explains why there are 352 rows when I should only have results for 351 cities and towns). Most importantly, though, all the results columns came in as character strings instead of numbers.
## City/Town V2 V3 Baker/ Polito Coakley/ Kerrigan Falchuk/ Jennings
## 347 Woburn NA NA 7,381 5,772 383
## 348 Worcester NA NA 16,091 20,297 1,309
## 349 Worthington NA NA 228 310 38
## 350 Wrentham NA NA 3,037 1,325 139
## 351 Yarmouth NA NA 5,426 4,164 237
## 352 TOTALS NA NA 1,044,573 1,004,408 71,814
## Lively/ Saunders Mccormick/ Post All Others Blank Votes
## 347 101 105 11 145
## 348 353 345 57 527
## 349 4 1 0 14
## 350 34 39 5 39
## 351 53 212 7 97
## 352 19,378 16,295 1,858 28,463
## Total Votes Cast
## 347 13,898
## 348 38,979
## 349 595
## 350 4,618
## 351 10,196
## 352 2,186,789Figure 12.1: Viewing the last few rows of election data with tail().
This is one of the few cases where Excel is “smarter” than an R package. Open up the CSV in Excel, and it understands that “25,384” is a number. R, however, expects numbers to only have digits and decimal places. Once it sees a comma, it will “assume” a string unless there’s some code to tell it otherwise.
Fortunately, there’s an R package that understands numbers with commas by default when importing data: readr. So let’s re-import the files using readr’s read_csv() function:
ma_latest_election <- readr::read_csv(ma_gov_latest_available_file_name)
ma_previous_election <- readr::read_csv(ma_gov_previous_available_file_name)The total row is easy to get rid of. I could remove row 352 with ma_latest_election <- ma_latest_election[-352,] using bracket notation or slice(ma_latest_election, -352) with dplyr. Or, as in the last chapter, I could slice off the final row using dplyr’s n() function and the minus sign: ma_latest_election <- slice(ma_latest_election, -n()).
But to make a general recipe, I could also filter out any row that starts with “total”, “Total”, or “TOTAL”.
I’m not sure whether a total row will have “total”, “Total”, or “TOTAL”. But I don’t have to worry about that if I explicitly tell R to ignore case. The stringr package’s str_detect() function comes in handy here, with the syntax str_detect("mystring", "mypattern") when using case-sensitive matching and str_detect("mystring", regex("mypattern", ignore_case = TRUE)) to ignore case.
I’m also using the %<>% operator here.
If that code seems a little complicated, another way to do this is to temporarily change the City/Town column to all lower case and then use the simpler str_detect syntax:
tolower() here doesn’t permanently change the column to all lower case, but transforms it only for the purpose of checking for string matching. ! before str_detect signifies “doesn’t match”.
Next: It looks like there’s no data in columns X2 and X3. You can check to make sure by running unique(ma_latest_election$X2)) and unique(ma_latest_election$X3)) to view all the unique items in that column, or table() on each column to see a table of all available data.
To delete a column, you can manually set its value to NULL:
For deleting more than one column, dplyr’s select() might be a better choice: ma_latest_election <- select(ma_latest_election, -X2, -X3). The minus sign before column names means they should be removed instead of selected.
Even better, though, would be a function that deletes all columns that have nothing in them. There’s a function in the janitor package that does this: remove_empty().
As you might have guessed, remove_empty(ma_latest_election, which = "rows") would remove all empty rows.
R-friendly column names. To get ready for my main analysis, I’ll rename the columns to make them R friendly (getting rid of slashes and spaces) as well as chart friendly.
names(ma_latest_election) <- c("Place", "Baker", "Coakley", "Falchuk", "Lively",
"Mccormick", "Others", "Blanks", "Total")If I’m re-using this script in future elections, I’ll need to make sure to replace this with new candidate names. One strategy is to put the column names in the configuration area at the top of the file. Another is to mark every area that needs updating with a comment such as #### NEEDS REPLACING ####.
12.4.5 Step 5: Who won and by how much?
The previous section got the data ready for analysis in R. This section will do a few simple calculations to make it easy to see who won and by how much.
These are things I need to do with every spreadsheet of election results, unless that spreadsheet already includes columns for winners, vote percentages, and margins of victories. Instead of re-writing that code each time I analyze election data, I created a couple of functions in an R election utilitiess package that I can re-use. With those ready-to-use functions for processing election data, I find election calculations in R even easier than doing them in Excel.
I wrote these functions years ago, before creation of packages like purrr. The code is old, and could probably be rewritten more efficiently, but it works. You are welcome to use those functions, too, if you’d find them helpful, which are in my rmiscutils package.
Calculating a winner per row. It’s a multi-step operation in R to look across each row, find the largest vote total, get the name of the column with the largest number, and make sure to account for ties before determining who won in each row. The rmiscutils package’s elec_find_winner() function does this for you.
elec_find_winner() takes these arguments: 1) name of a file as a character string (in quotation marks) because it assumes you’re using the package to read in a CSV or Excel file, although "mydata" without a .csv or .xlsx extension will assume you want to use an already-existing data frame and convert the character string into an R data frame object for you; 2) the number of the column where candidate vote totals start; 3) the number of the column where candidate vote totals end; and 4) whether you want to export the results to a CSV file.
This function calculates a winner for each row, as long as the data is formatted as the function expects: each candidate’s vote total is in its own column, and each place (city, precinct, state, etc.) is in its row. And, it returns both candidates’ names if there’s a tie.
For the 2014 Massachusetts election data, the command would be:
By specifying columns 2:5, I excluded write-ins, blanks, and the Total column when calculating the winner. The function creates a new Winner column.
I can do a quick check of how many cities and towns each candidate won by counting items in the Winner column with base R’s table() function:
##
## Baker Coakley
## 232 119Victory margins. This data has raw vote totals, but I’m also interested in vote percentages for each candidate in each place. Percents can answer the question “Where were each candidate’s strengths?”
Percents can also better show at a glance how polarized an outcome was. A race can be close overall and close in most communities, or it can be close overall but with many communities voting heavily for one side or the other. Looking at a map or chart showing only which candidate won misses a key part of the story: Winning by 1 point isn’t the same as winning by 12.
Other interesting questions that percent margins-of-victory can answer, especially for a close election: “How close was each community?”" (or state, or precinct, depending on your level of analysis), and “How many communities were competitive?”
But percents alone miss another part of the story, because there’s a difference between winning by 5 points in Boston and winning by 5 points in Bolton. Electoral strength in a major city can be worth tens of thousands of votes in padding a victory margin; winning a small town by the same margin could net just a few dozen. So, I also like to calculate how many net votes the winner received versus his or her nearest challenger in each community. That answers the question, “What areas helped most in winning the election?”
In Massachusetts, Boston has the largest number of votes of any community by far, and Democrats almost always win there. But for Democrat Martha Coakley in 2014, winning Boston handily didn’t give her an overall victory – she didn’t run up her overall vote total enough to offset Republican Charlie Baker’s strength elsewhere. Comparing results with prior elections would be helpful here to understand what happened.
One possibility is that she won Boston by a slimmer percent margin than Democratic Gov. Deval Patrick did before her. Another possibility is that she won Boston by similar margins as Patrick did, but turnout was lower in the city than in prior years. Yet another possibility is that all was the same in Boston as when Patrick won, but pro-Baker areas had higher turnout.
However, one step at a time. Let’s first get 2014 data in shape for some basic analysis.
My rmiscutils package’s elec_pcts_by_row() function will generate percents for each value across a row. If the data is formatted like this
## Place Baker Coakley Total
## 1 Abington 3459 2105 5913
## 2 Acton 3776 4534 8736
## 3 Acushnet 1500 1383 3145elec_pcts_by_row() can calculate Baker’s percent and Coakley’s percent versus the overall Total in each row. The syntax is elec_pcts_by_row(mydata, c("candidate1", "candidate2"), "TotalColumn") (the total column name expects the total column to be named “Total” so it won’t be necessary to define it here.) Note I’m also using magrittr’s %<>% so I don’t have to keep writing out winners <- winners %>% , but if that’s less understandable for you, feel free to keep using “wordier” syntax.
library(dplyr)
library(magrittr)
winners <- elec_pcts_by_row(winners, c("Baker", "Coakley"))
winners %<>%
mutate(
Baker.pct.margin = Baker.pct - Coakley.pct,
Baker.vote.margin = Baker - Coakley
)I’m not interested in the third-party candidates, write-ins, blanks, or the lower-case place column right now, so I’ll remove columns 4 through 8 for streamlined analysis.
If you want to use this for analyzing another election, you could simply replace “Baker” and “Coakley” here; and then change the new column names from Baker.pct.margin and Baker.vote.margin to Winner.pct.margin and Winner.vote.margin.)
A basic summary() will check the data (see Figure 12.2):
## Place Baker Coakley Total
## Length:351 Min. : 20 Min. : 11.0 Min. : 36
## Class :character 1st Qu.: 704 1st Qu.: 691.5 1st Qu.: 1654
## Mode :character Median : 2189 Median : 1424.0 Median : 3869
## Mean : 2976 Mean : 2861.6 Mean : 6230
## 3rd Qu.: 4205 3rd Qu.: 3215.0 3rd Qu.: 8286
## Max. :47653 Max. :104995.0 Max. :161115
## Winner Baker.pct Coakley.pct Baker.pct.margin
## Length:351 Min. :13.30 Min. :21.10 Min. :-68.800
## Class :character 1st Qu.:38.55 1st Qu.:34.00 1st Qu.:-12.850
## Mode :character Median :53.70 Median :39.90 Median : 13.800
## Mean :49.22 Mean :43.75 Mean : 5.472
## 3rd Qu.:59.50 3rd Qu.:51.80 3rd Qu.: 25.250
## Max. :69.80 Max. :82.10 Max. : 48.200
## Baker.vote.margin
## Min. :-57342.0
## 1st Qu.: -105.5
## Median : 431.0
## Mean : 114.4
## 3rd Qu.: 1227.0
## Max. : 4222.0Figure 12.2: A summary of the winners data frame.
Next, there are some other dataviz “basics” I’d like to run on election data to find out who had the largest vote margins and percent victory margins, and where it was closest.
12.4.6 Step 6: Exploratory visualizations
There are two different types of visualizing you’re probably going to want to do if you’re covering an election. Exploratory visualizations will help you better understand the data and decide what stories you want to tell with it. These don’t have to be pretty or well labeled; they just need to help you see patterns. Presentation visualizations are for your audience, and so need to be constructed with a bit more care.
For quick visualizations, base R’s hist() on the Baker.pct.margin column will give a sense of how many communities were close vs. blowouts:

Figure 12.3: A histogram of Baker’s winning percent margins.
You can see in Figure 12.3 that Baker had a few big losses/Coakley had a few big wins, but the most common results had Baker winning by between 10 and 30 percentage points.
What about actual margin of victory in raw votes? That’s the Baker.vote.margin column:

Figure 12.4: A histogram of Baker’s winning vote totals.
It looks in Figure 12.4 like Baker won a lot communities by small vote totals – either because large communities were close or he won in a lot of small towns. Later in this chapter, we’ll take a look at that.
The way these election results are structured, Baker’s largest margins are positive numbers and Coakley’s largest margins are negative numbers, because I calculated data for the winning candidate, Charlie Baker. However, I’m also curious to see the largest margins regardless of who won. For this case, then, I want the absolute values of Baker’s vote margins, turning everything into a positive number. Otherwise, if I pull “largest vote margins,” I’ll only get Baker’s top margins and won’t see Coakley’s top raw-vote wins.
I’ll use dplyr’s top_n() function to view the top 5 rows. top_n() takes the syntax top_n(dataframe, numrows, sortingcolumn). :
## Place Baker Coakley Total Winner Baker.pct Coakley.pct
## 1 Boston 47653 104995 161115 Coakley 29.6 65.2
## 2 Cambridge 5589 25525 32725 Coakley 17.1 78.0
## 3 Newton 12089 19068 33019 Coakley 36.6 57.7
## 4 Somerville 4918 16351 22844 Coakley 21.5 71.6
## 5 Springfield 10256 19312 34375 Coakley 29.8 56.2
## Baker.pct.margin Baker.vote.margin
## 1 -35.6 -57342
## 2 -60.9 -19936
## 3 -21.1 -6979
## 4 -50.1 -11433
## 5 -26.4 -9056Coakley, the loser, had the five largest raw-vote wins, including winning the state’s largest city by a very healthy margin.
Unfortunatey, top_n() isn’t arranging these from largest to smallest, but you can do that by adding arrange() to sort by Baker’s vote margin in descending order (don’t forget to take the absolute value):
Which communities had the narrowest margins by percent? I’ll again take an absolute value, this time of the Baker.pct.margin column, and look at the bottom 5 to get the smallest margin. To get the lowest 5 instead of largest 5, use -5 as top_n()’s second argument and not 5:
top_n(winners, -5, abs(Baker.pct.margin)) %>%
select(Place, Baker.pct, Coakley.pct, Baker.pct.margin) %>%
arrange(abs(Baker.pct.margin))## Place Baker.pct Coakley.pct Baker.pct.margin
## 1 Westport 46.6 46.4 0.2
## 2 Natick 47.2 47.7 -0.5
## 3 Orleans 48.4 47.6 0.8
## 4 Milton 48.6 47.7 0.9
## 5 Carlisle 48.4 47.0 1.4
## 6 Wayland 48.8 47.4 1.4Note that I got 6 rows back, not 5, because the towns of Carlisle and Wayland were tied at 1.4%. (I selected four columns here so there would be enough room to print out the important columns on this page.)
There are more of these types of highest and lowest results that would be interesting to see, but it starts getting tedious to write out each one. It feels a lot easier to do this by clicking and sorting a spreadsheet than writing out code for each little exploration. If you’d like to re-create that in R, you can view the winners data frame by clicking on it in the Environment tab at the top right, or running View(winners) in the console. Clicking on a column header once sorts by that column in ascending order; clicking a second time sorts the data frame by that column in descending order. This is a nice if unstructured way to view the data.
An even better way of doing this is with the DT package, which will create an interactive HTML table. Install it from CRAN, load it, and then run its datatable function on the data frame, just like this:
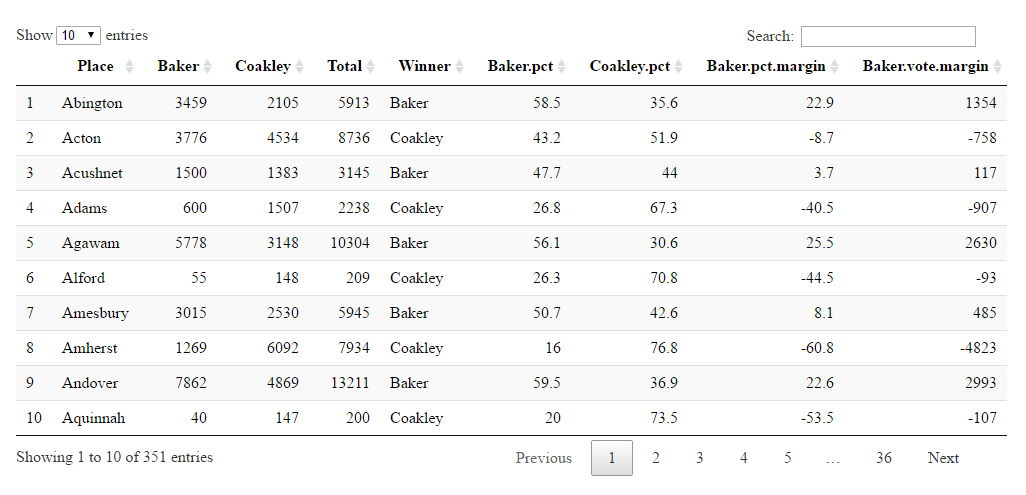
Figure 12.5: A sortable, searchable table created with the DT package.
You’ll get an HTML table that’s sortable and searchable (see Figure 12.5). The table first appears in RStudio’s viewer; but you can click the “Show in new window” icon (to the right of the broom icon) and the table loads in your default browser.
The DT package’s Web site at https://rstudio.github.io/DT/ gives you a full range of options for these tables. A few I use very often:
datatable(mydf, filter = 'top')adds search filters for each columndatatable(mydf) %>% formatCurrency(2:4, digits = 0, currency = "")displays the numbers in columns 2:4 with commas (digits = 0means don’t use numbers after a decimal point, andcurrency = ""means don’t use a dollar sign or other currency symbol)datatable(mydf, options = list(pageLength = 25))sets the table default to showing 25 rows at a time instead of 10.datatable(mydf, options = list(dom = 't'))shows just the sortable table without filters, search box, or menu for additional pages of results – useful for a table with just a few rows where a search box and dropdown menu might look silly.
Although I’ve been using the DT package for years, I still find it difficult to remember the syntax for many of its options. Like with ggplot2, I solved this problem with code snippets, making it incredibly easy to customize my tables. For example, this is my snippet to create a table where a numerical columns displays with commas:
snippet my_DT_add_commas
DT::datatable(${1:mydf}) %>%
formatCurrency(${colnum}, digits = 0, currency = "")(If I have more than one numerical column, it’s easy enough to replace one column number with several.) All my DT snippets start my_DT_ so they’re easy to find in an RStudio dropdown list if I start typing my_DT.
One more benefit of the DT package: It creates an R HTML Widget. This means you can save the table as a stand-alone HTML file. If you save a table in an R variable, you can then save that table with the htmlwidgets::saveWidget() function:
MA2014_results <- datatable(winners, filter = 'top') %>%
formatCurrency(2:4, digits = 0, currency = "")
htmlwidgets::saveWidget(MA2014_results, file = "MA2014_results_table.html")If you run that, you should see a MA2014_results_table.html file in your project’s working directory. As with maps in the previous chapter, you can open this file in your browser just like any local HTML file. You can also upload it to a Web server to display directly or iframe on your website – useful for posting election results online.
That table also makes interactive data exploration easier. I can filter for just Baker’s wins or Coakley’s wins, sort with a click, use the numerical filters’ sliders to choose small or large places, and more.